
From Faculty of Electronic Information and Electrical Engineering
By Zhang Jiawei, Jing Jiayi, Sun Yuanyuan
Natural Language Processing (NLP), an important branch of artificial intelligence, applies computer technology to process, understand and exploit natural language. At present, NLP is used in various fields, such as machine translation, personalized recommendation, information searching, screening and filtering, character recognition and speech recognition, opinion analysis, etc, and has broad research and application prospects. Recently, Information Retrieval Laboratory (DUTIR) of School of Computer Science and Technology, Dalian University of Technology (DUT) has made a series of breakthroughs in the field of NLP and many scientific research results have been accepted by top conferences and journals in the field of NLP.

Since the wanton dissemination of hate speech on the Internet has caused great harm to society and families, it is urgent to establish and improve the automatic detection and active avoidance system for hate speech. Current methods for hate speech detection suffer from “inherent biases” in the training process due to their stereotypes of words. The results of the research team, focusing on hate speech detection and active avoidance system on the Internet, were reported in Hate Speech Detection Based on Sentiment Knowledge Sharing. The paper was accepted by the top NLP conference, Association for Computational Linguistics 2021 (ACL2021, CCF A-Level Conference). The research proposed a hate speech detection framework based on shared emotional knowledge. With the framework, the system can make better use of the emotional features in external resources and integrate features from different feature extraction units to detect hate speech while extracting the emotional features of the target sentence.
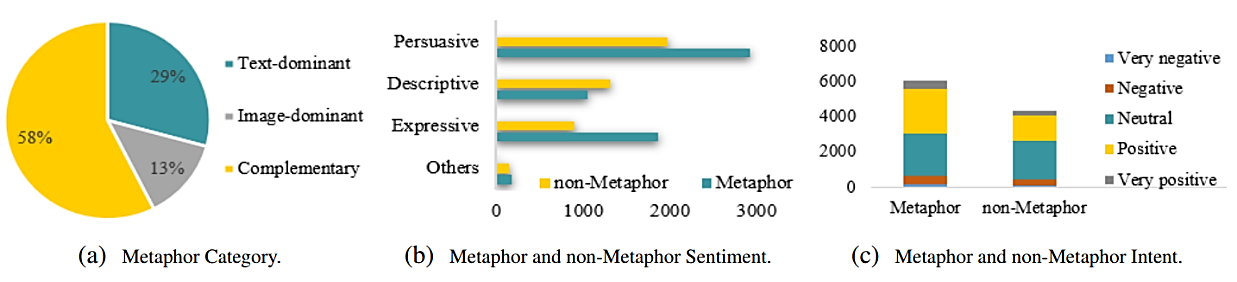
Metaphor is a very common language recognition phenomenon and metaphor computation is one of the most challenging problems in NLP. However, due to the lack of multimodal metaphor data, most metaphor research is currently limited to the recognition of metaphor phenomena in the text. To solve the problem mentioned above, the team focused on the establishment of data set to provide high-quality data for multimodal computational metaphor research. The research result, MultiMET: A Multimodal Dataset for Metaphor Understanding, was accepted by the top NLP conference, Association for Computational Linguistics 2021 (ACL2021, CCF A-Level Conference). The research used platforms with high frequency of multimodal metaphors such as social media and advertisements as the main source of data, standardized the concept definition and classification of multimodal metaphors, and established a multi-link quality monitoring mechanism. Utilizing statistics to analyze and verify data, the first large-scale and high-quality multimodal metaphor data set was proposed. At the same time, a series of baseline experiments were conducted based on the multimodal data set and the importance of multimodal data to metaphor recognition was demonstrated by the interaction between multimodal data. The study extends the metaphor computation from pure text to multimodality field, promotes the development of multimodal metaphor computation, and provides a new direction for metaphor recognition in the future. Thus it is important for the development of implicit semantics research.

The team conducted research on the joint learning of slot filling and intent detection in dialogue tasks of NLP, Focus on Interaction: A Novel Dynamic Graph Model for Joint Multiple Intent Detection and Slot Filling, was accepted by the top artificial intelligence conference, International Joint Conference on Artificial Intelligence 2021 (IJCAI2021, CCF A-Level Conference). Understanding spoken language is an important part of task-oriented dialogue, consisting of two subtasks: slot filling and intent detection. However, due to the error propagation of Pipeline (sequential processing according to the specified order in the field of computer) and the high correlation between the two tasks, joint learning is often better than Pipeline method. Current joint learning mostly aims at single intent situations, but in real situations, users often express multiple intents in one sentence. The study proposed a dynamic graph model for slot filling and multiple intent detection. The model can directly establish connections between the two tasks and the dynamic interaction graph can effectively reduce noise. At the same time, the model can dynamically update the interaction graph in the training process, so as to better establish the relationship between intent and slot and improve the friendly interaction of man-machine dialogue.

Semantic network is a widely existing graph-structured data. Associated fact prediction based on semantic network is an important way to mine the hidden knowledge in the network for it can explore the potential and valuable association relationships between facts. Previous methods for associated fact prediction focus more on the topological features of the network but ignore the role of semantic information. The results of the team focusing on the multi-dimensional modeling and knowledge mining of the semantic network are reported in A Semantic Network Encoder for Associated Fact Prediction. The article is published in the influential journal in the field of data mining, IEEE Transaction on Knowledge and Data Engineering (TKDE, CCF A-Level Journal). The study proposes a semantic network encoder, which can adapt to various forms of semantic network and jointly model the topological and semantic features of the network. Meanwhile, the word self-organization method based on fact boundaries built in the encoder can integrate the semantic and topological features of the same fact, thereby enhancing the information expression ability of fact vectors.
DUTIR focuses on NLP technology and studies information retrieval, emotional computing, biomedicine, smart justice, data mining, knowledge graph, man-machine dialogue, etc., based on deep learning and machine learning. The research results of the team in recent years have been published in important international conferences and journals such as ACL, IJCAI, WWW, SIGIR, EMNLP, COLING, TKDE, and Bioinformatics. Based on scientific research, the lab actively explores major national strategic needs and undertakes national key research and development programs such as Evidence Correlation Analysis of Public Prosecution Cases and Case Auxiliary Judgment, Court Trial Response Strategies and Establishment of Court Trial Plan Based on the Identification of Prosecution and Defence Focus, Research on the Automatic Construction and System Development of the Profile the Litigants Involved, Knowledge Network Construction of Precise Medical Texts, etc.
Editor: Li Xiang


